AHP(层次分析法)
AHP(层次分析法)
[TOC]
一、AHP层次分析法是什么?
AHP(Analytic Hierarchy Process)层次分析法是美国运筹学家T. L. Saaty教授于二十世纪70年代提出的一种实用的多方案或多目标的决策方法,是一种定性与定量相结合的决策分析方法。用决策者的经验判断各衡量目标之间能否实现的标准之间的相对重要程度,并合理地给出每个决策方案的每个标准的权数,利用权数求出各方案的优劣次序,比较有效地应用于那些难以用定量方法解决的课题。,具有十分广泛的实用性。
二、AHP的广泛运用
经过四十多年的研究与发展,AHP已经成为决策者广泛使用的一种多准则方法。其应用涉及经济与计划、能源政策与资源分配、政治问题及冲突、人力资源管理、预测、项目评价、教育发展、环境工程、企业管理与生产经营决策、会计、卫生保健、军事指挥、武器评价、法律等众多领域。AHP主要是作为一种辅助决策工具,它只有和其他方法有机结合,才能取得比较好的使用效果。从现有的研究成果看,与AHP结合使用的其他方法有模糊集理论、模糊逻辑、数字规划、成本收益分析、人工神经网络、证据推理、数据包络分析、仿真、数据挖掘等。
三、AHP的优缺点
1.层次分析法的优点
-
系统性-将对象视作系统,按照分解、比较、判断、综合的思维方式进行决策。成为成为继机理分析、统计分析之后发展起来的系统分析的重要工具;
- 实用性-定性与定量相结合,能处理许多用传统的最优化技术无法着手的实际问题,应用范围很广,同时,这种方法使得决策者与决策分析者能够相互沟通,决策者甚至可以直接应用它,这就增加了决策的有效性;
- 简洁性-计算简便,结果明确,具有中等文化程度的人即可以了解层次分析法的基本原理并掌握该法的基本步骤,容易被决策者了解和掌握。便于决策者直接了解和掌握。
- 建立所有要素(包括非量化与量化)的层级,清楚呈现各层、各准则与各要素的关系。
- 简化评估程序,计算过程简单易懂。
- 若研究资料存在遗漏或不足的部分,仍能求得各要素的重要性。
2.层次分析法的缺点
- 囿旧-只能从原有的方案中优选一个出来,没有办法得出更好的新方案;
- 粗略-该法中的比较、判断以及结果的计算过程都是粗糙的,不适用于精度较高的问题。;
- 主观-从建立层次结构模型到给出成对比较矩阵,人主观因素对整个过程的影响很大,这就使得结果难以让所有的决策者接受。当然采取专家群体判断的办法是克服这个缺点的一种途径。
- 要素之间两两比较有时比较困难。
- 当要素比较多时,一致性检验可能无法通过(所以一般把要素控制在7个)。
- 分析时没有考虑要素的相关性问题。
四、应用步骤
运用层次分析法构造系统模型时,大体可以分为以下四个步骤:
建立层次结构模型
构造判断(成对比较)矩阵
层次单排序及其—致性检验
层次总排序及其一致性检验
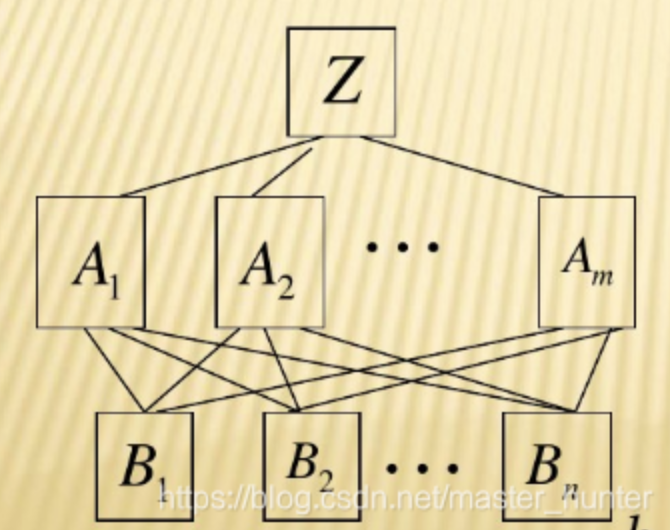
1、建立层次结构模型
将决策的目标、考虑的因素(决策准则)和决策对象按它们之间的相互关系分为最高层、中间层和最低层,绘出层次结构图。
- 最高层:决策的目的、要解决的问题。
- 最低层:决策时的备选方案。
- 中间层:考虑的因素、决策的准则。
对于相邻的两层,称高层为目标层,低层为因素层。
例如某单位拟从3名干部中选拔一名领导,选拔的标准有政策水平、工作作风、业务知识、口才、写作能力和健康状况。我们建立层次结构模型就为:

2.构造判断(成对比较)矩阵
在确定各层次各因素之间的权重时,如果只是定性的结果,则常常不容易被别人接受,因而有人提出:一致矩阵法,即:
- 不把所有因素放在一起比较,而是两两相互比较。
- 对比时采用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,以提高准确度。
- 判断矩阵是表示本层所有因素针对上一层某一个因素的相对重要性的比较。判断矩阵的元素aj;用Santy的1—9标度方法给出。

在依据上述给的选举领导的例子,我们构造判断矩阵为:

3.层次单排序及其—致性检验
对应于判断矩阵最大特征根入max的特征向量,经归一化(使向量中各元素之和等于1)后记为W。
W的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序。
能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对A确定不一致的允许范围。
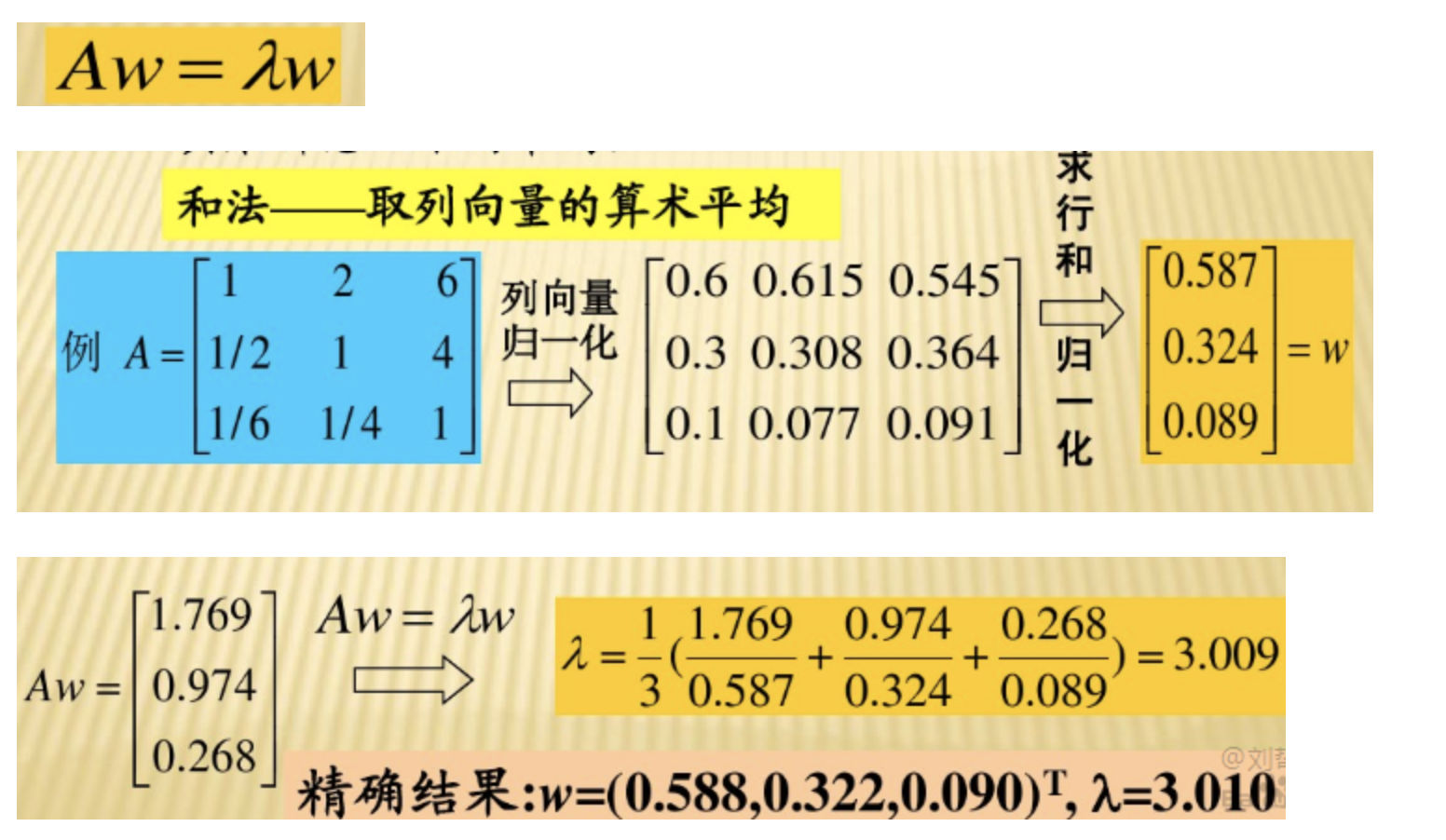
首先我们要先对我们构造的比较矩阵进行归一化:
列向量归一化:求每个分量平方和,然后求它的平方根
再给每个分量除以上面得到的数就可以了

(1)计算一致性指标

(2)为了衡量的大小,引入随机一致性指标
查找相应的平均随机一致性指标RI。对n=1,…,9,Santy给出了RI的值,如下表(表2):

(3)计算一致性比例CR:

4.层次总排序及其一致性检验
计算某一层次所有因素对于最高层(总目标)相对重要性的权值,称为层次总排序。这一过程是从最高层次到最低层次依次进行的。



五、Python 代码
1 | |
六、参考链接
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!