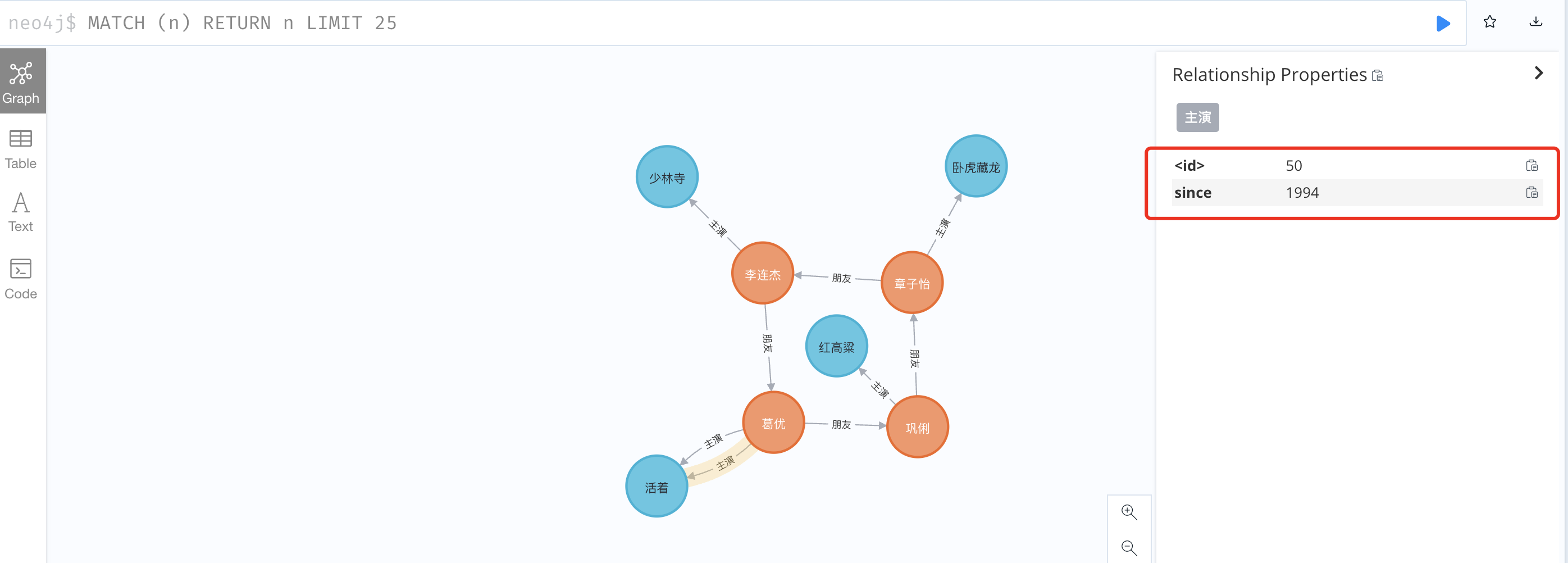
MATCH (a:Person {name:'葛优'}), (b:Movie {name:'活着'}) MERGE (a)-[:主演 {since:1994}]->(b)
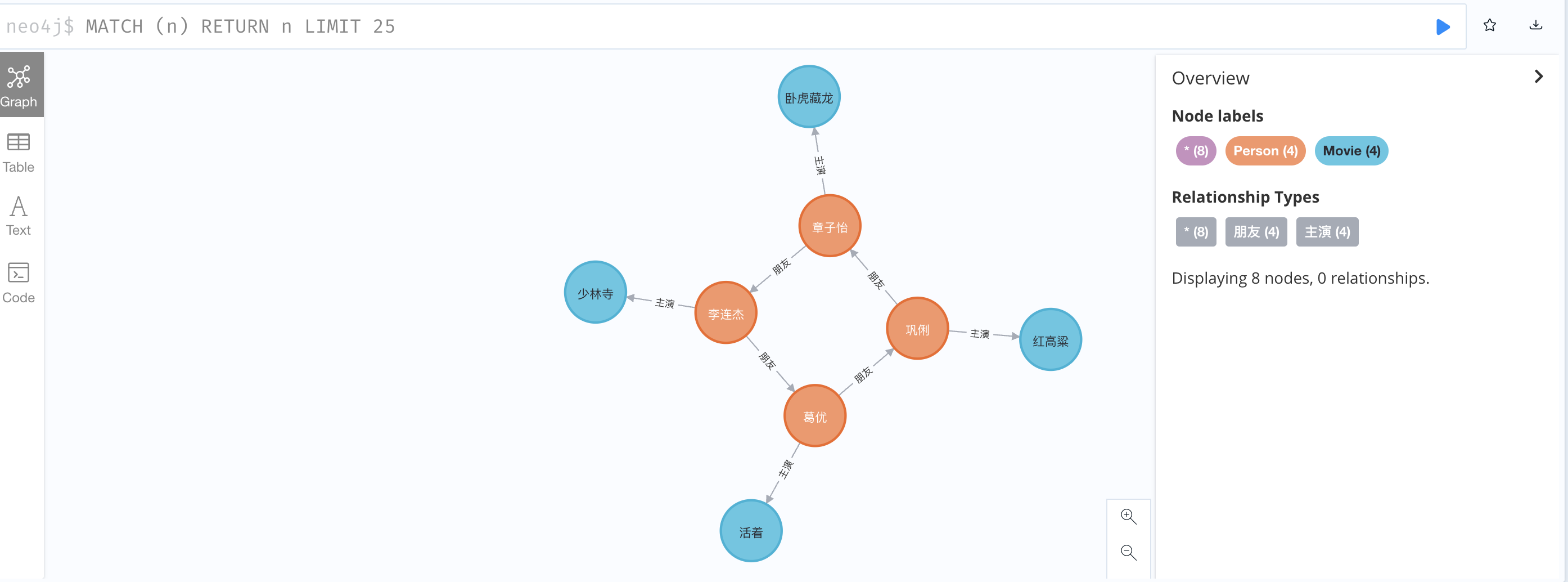
4、查询数据
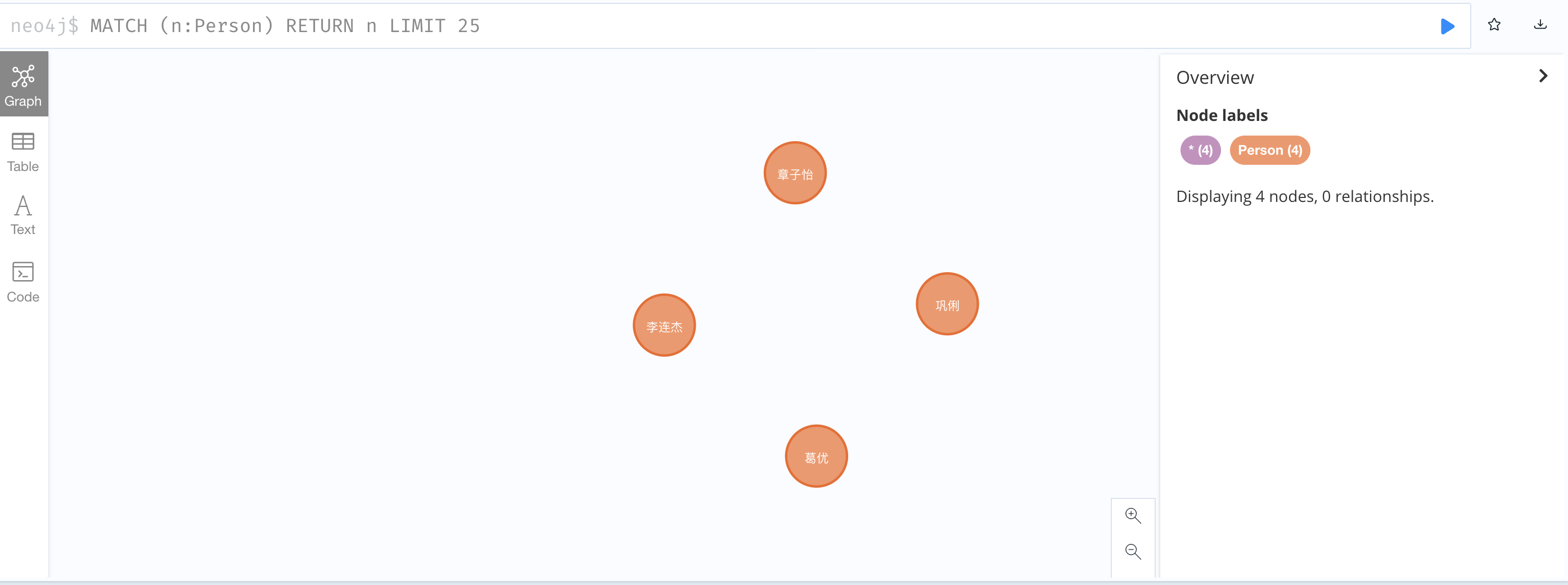
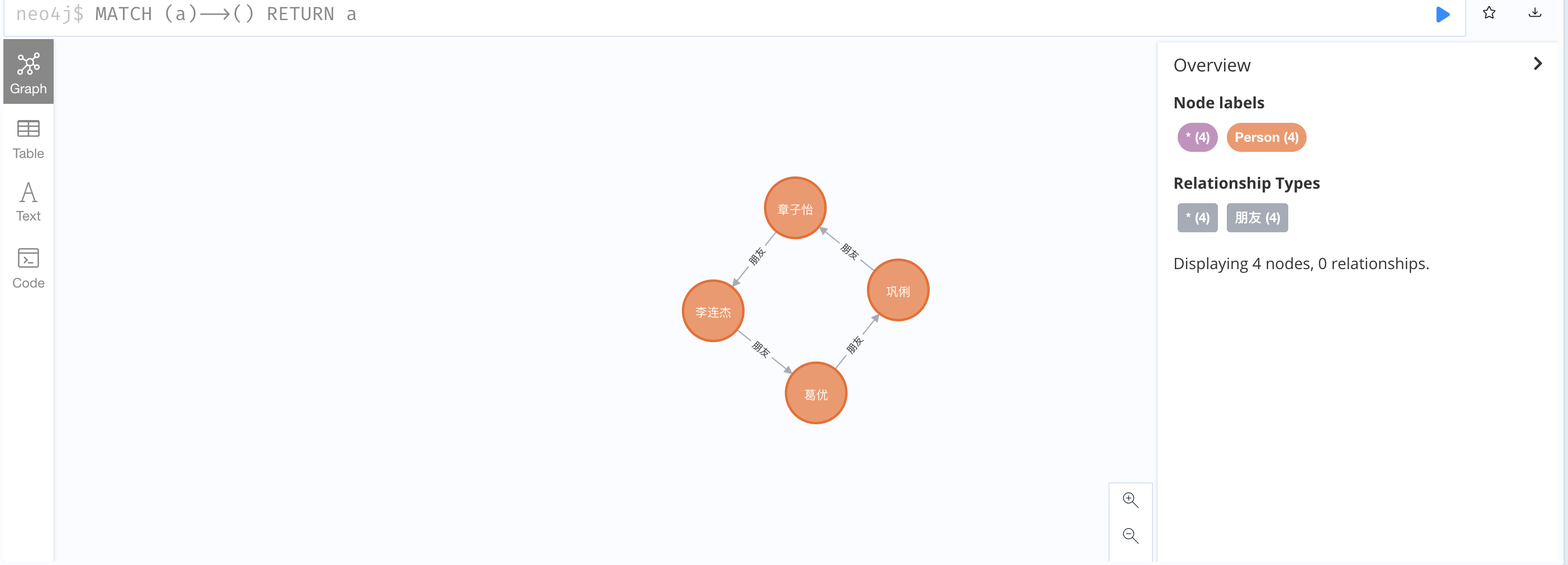
1、查询所有对外有关系的节点
1
MATCH (a)-->() RETURN a;
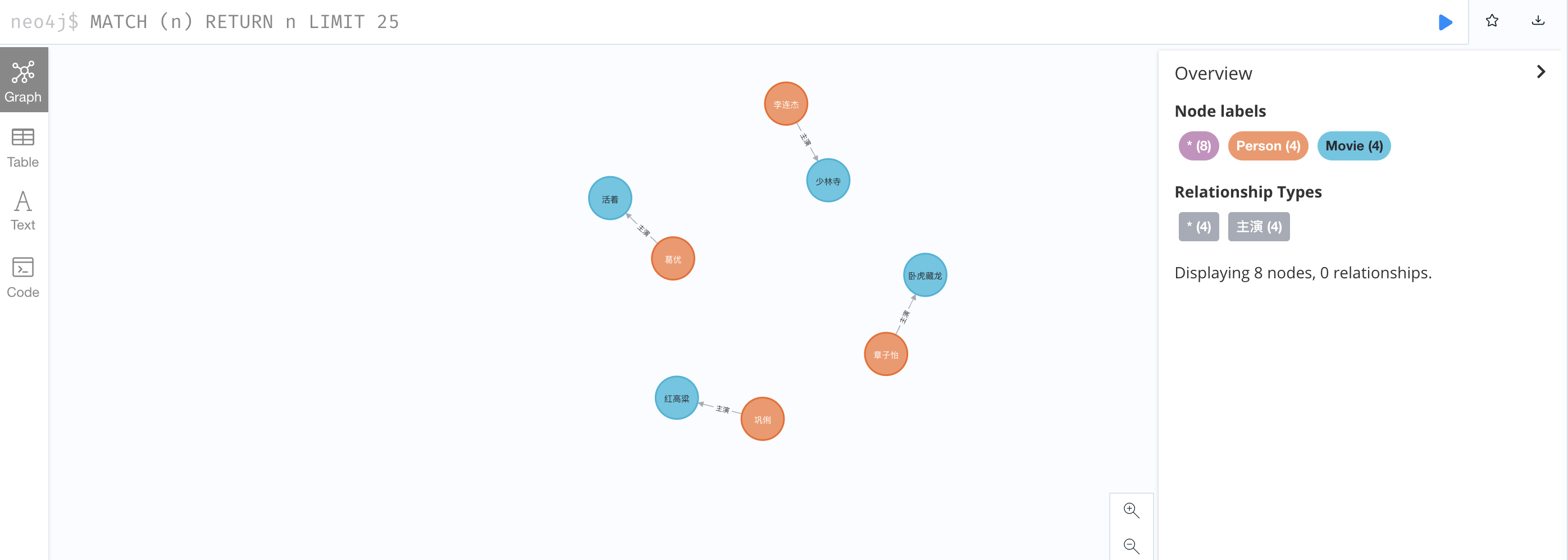
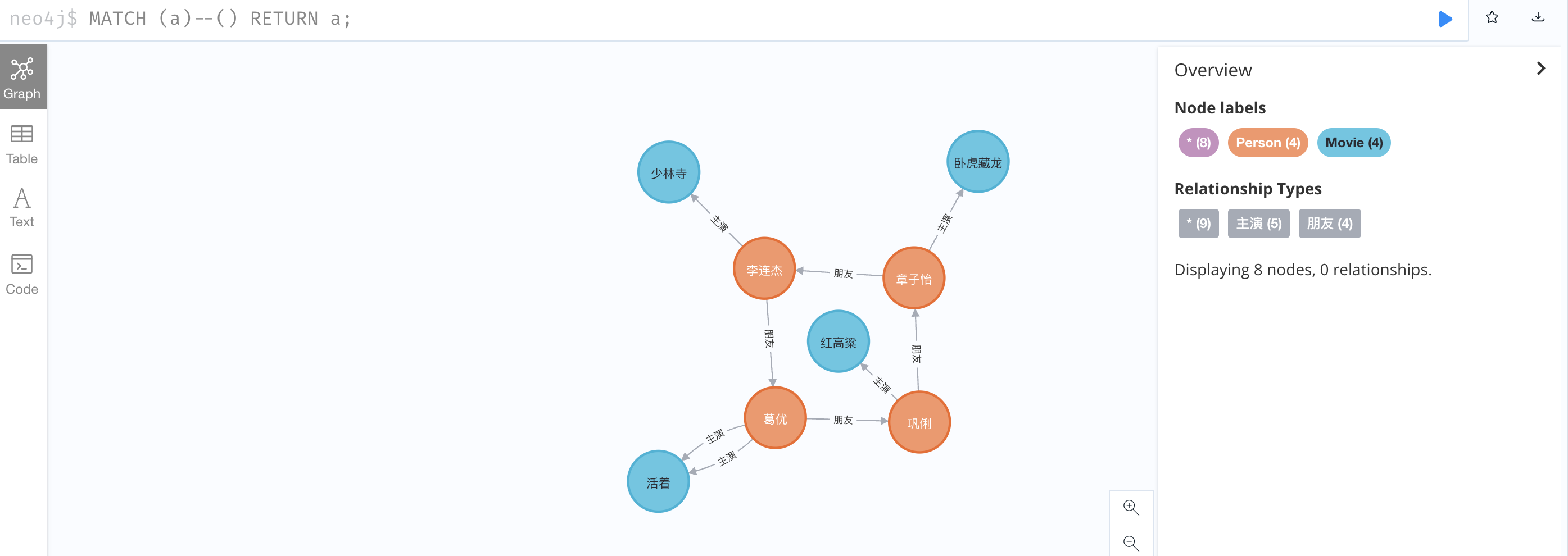
2、查看所有有关系的节点
1
MATCH (a)--() RETURN a
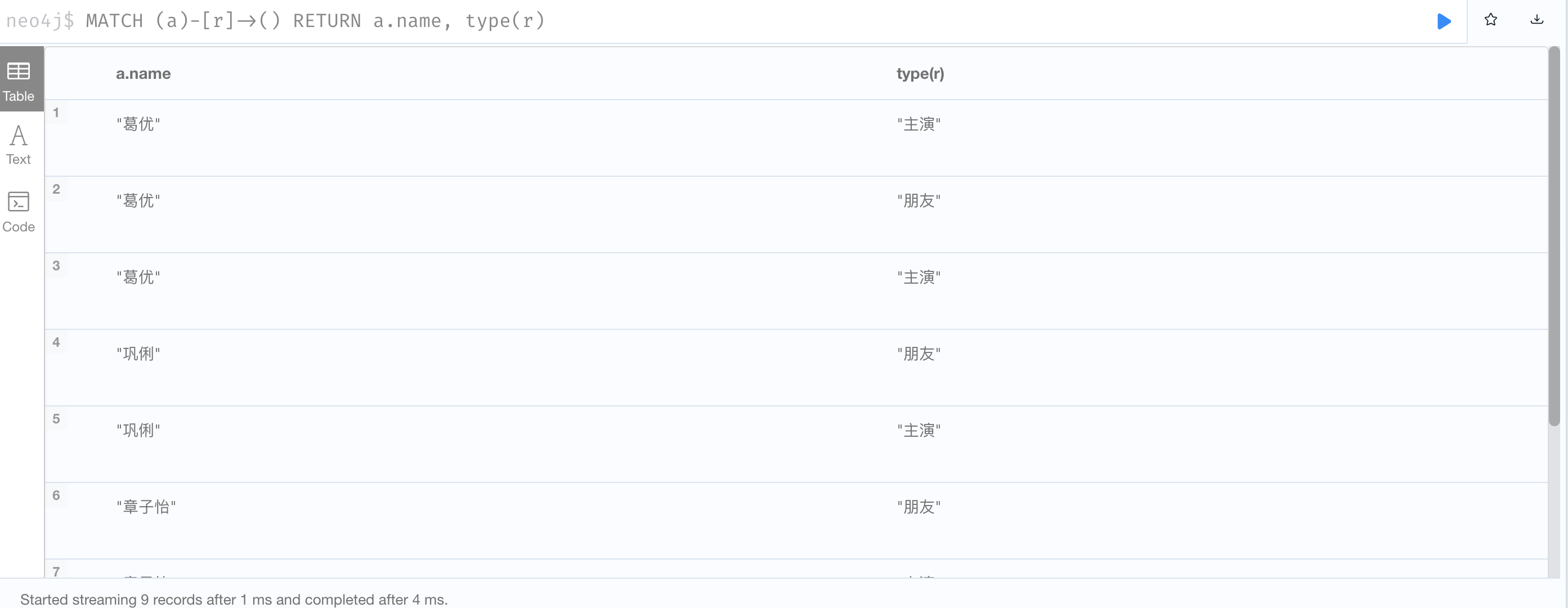
3、查看所有对外有关系的节点,以及关系类型
1
MATCH (a)-[r]->() RETURN a.name, type(r);
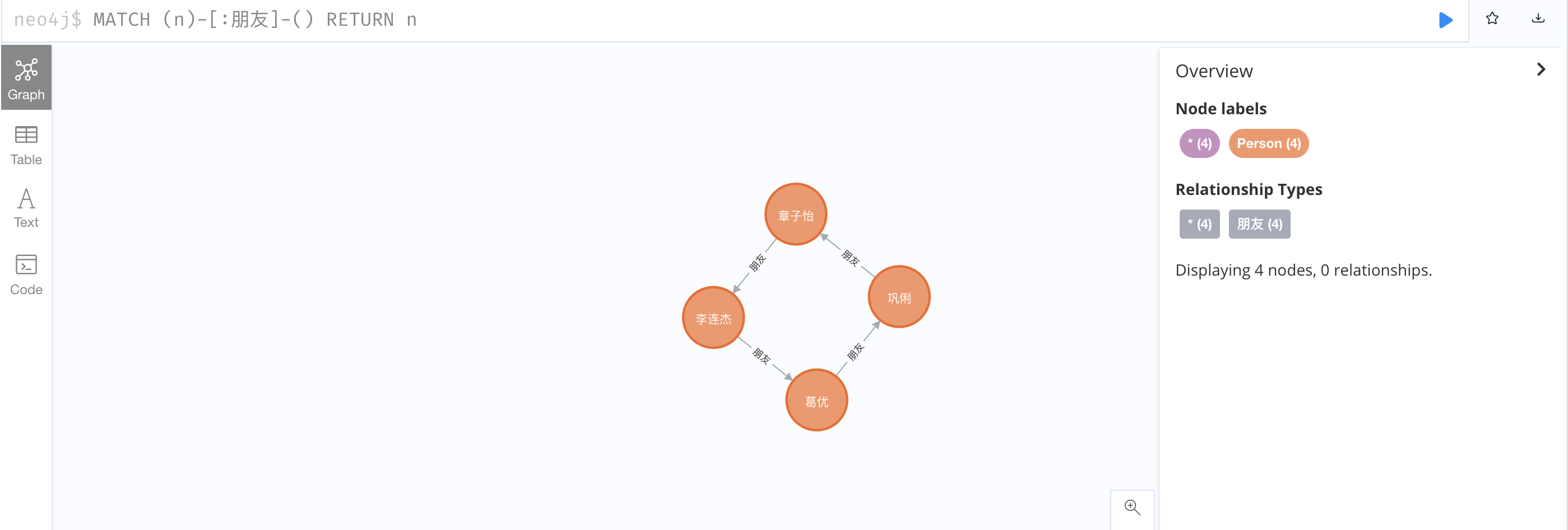
4、查看所有有朋友关系的节点
1
MATCH (n)-[:朋友]-() RETURN n;
5、查看某人的朋友的朋友
1
MATCH (a:Person {name:'葛优'})-[r1:朋友]-()-[r2:朋友]-(friend_of_a_friend) RETURN friend_of_a_friend.name AS fofName
葛优朋友的朋友就是章子怡
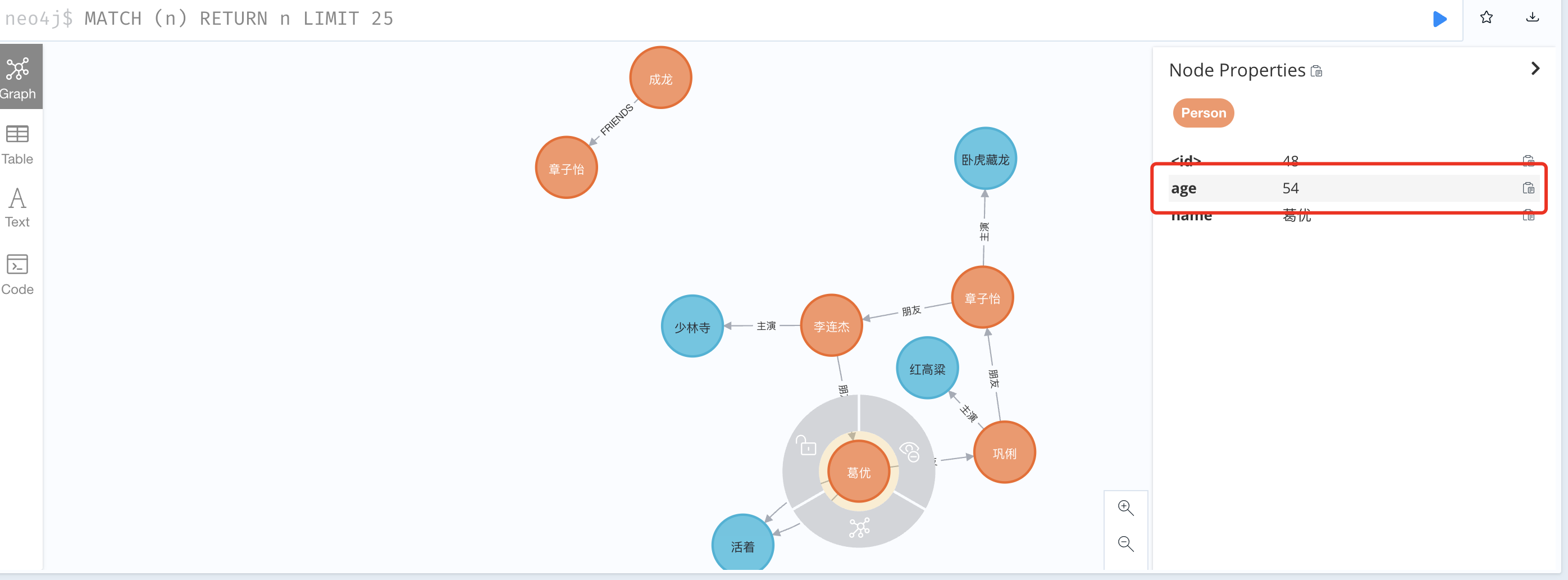
5、修改节点、属性
1 2
MATCH (a:Person {name:'葛优'}) SET a.age=54; MATCH (a:Person {name:'章子怡'}) SET a.age=44;
6、删除节点、属性、关系
1、删除节点
删除节点前需要将节点的关系等数据删除,否则会报错(Cannot delete node<50>, because it still has relationships. To delete this node, you must first delete its relationships.)
1
MATCH (a:Person {name:'章子怡'}) DELETE a;
2、删除节点属性
1 2
MATCH (a:Person {name:'葛优'}) SET a.test='test'; MATCH (a:Person {name:'葛优'}) REMOVE a.test;
3、删除有关系的节点
1
MATCH (a:Person {name:'葛优'})-[rel]-(b:Person) DELETE a,b,rel;
4、删除关系
删除指定两个节点的关系
1 2
MATCH (:Person {name: "葛优"})-[r:朋友]-(:Person {name: "巩俐"}) DELETE r
删除全部节点的某种关系
1 2 3 4 5
MATCH (:Person)-[r:朋友]-(:Person) DELETE r
MATCH ()-[r:朋友]-() DELETE r
7、批量导入节点、关系
a.csv
b.csv
c.csv
d.csv
1、导入演员节点
1
LOAD CSV WITH HEADERS FROM 'file:///a.csv' AS line FIELDTERMINATOR ',' CREATE (:Person {name: line.name});
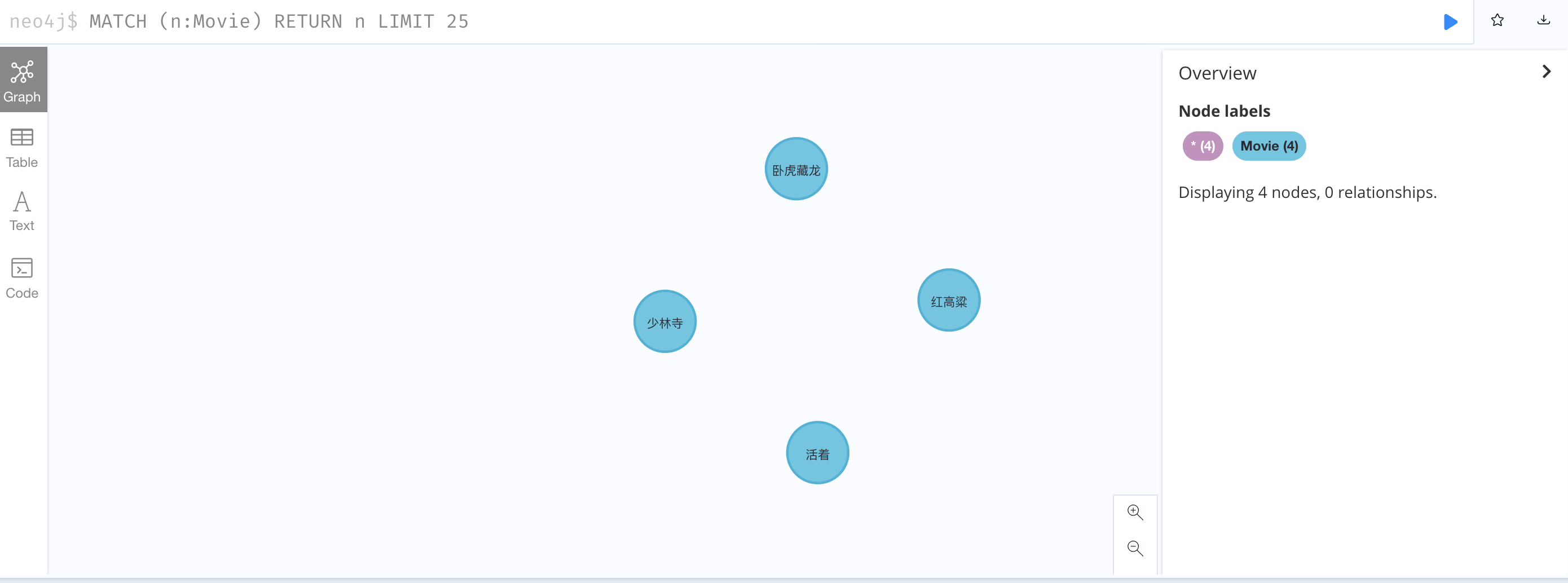
2、导入电影节点
1
LOAD CSV WITH HEADERS FROM 'file:///b.csv' AS line FIELDTERMINATOR ',' CREATE (:Movie {name: line.name});
3、增加演员与电影的关系
1
LOAD CSV WITH HEADERS FROM "file:///c.csv" AS line MATCH (from:Person{name:line.person}),(to:Movie{name:line.movie}) MERGE (from)-[r:relation {Relation:line.relation}]->(to)
4、增加演员之间的关系
1
LOAD CSV WITH HEADERS FROM "file:///d.csv" AS line MATCH (from:Person{name:line.one}),(to:Person{name:line.two}) MERGE (from)-[r:relation {Relation:line.relation}]->(to)